
如何从实验转向构建生产机器学习应用程序
时间: 2019-07-01来源: Nisha Talagala

将机器学习(ML)实验从笔记本电脑或数据科学实验室进行到生产的过程并不是很多人都有过的经验。数据科学家们经常肩负着这项艰巨的任务,因为他们了解机器学习算法,而且很可能是他们首先提出的。
这篇文章描述了如何开始一个成功的生产机器学习业务生命周期(MLOps),通过在生产服务中从一个有前景的ML实验转移到相同算法的最小可行性产品(MVP)。MVP在产品开发中很常见,因为它们可以帮助客户快速获得产品/服务,只要有足够的特性使其可行,并推动下一个基于使用反馈的版本。在机器学习上下文中,MVPs帮助分离生产ML服务的关键需求,并帮助以更小的努力交付它。
我们描述的生产机器学习MVP的步骤是从过去几年与数据科学家和组织的数百个用例和经验中总结出来的。如下图所示:
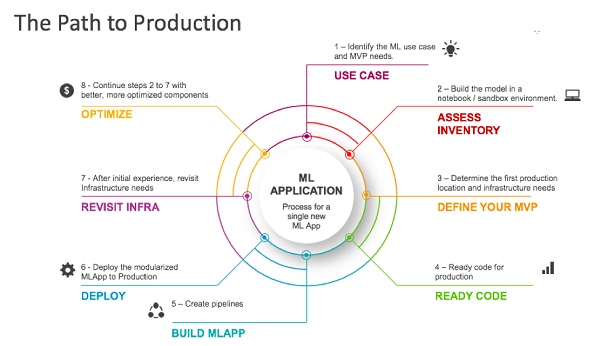
图1:从开发人员实验到生产ML的路径
步骤1:确定您的用例:您想要做什么?
这似乎是显而易见的,但是第一步是了解您的业务应用程序的的更低需求是什么,以及您的实验和更低需求之间的差距。例如,如果您的实验假设可用的特性比业务应用程序能够提供的特性更多,那么这种差距可能会影响生产。找到这种差距的更佳方法是定义支持您的业务应用程序的机器学习应用程序。
以下是一些你需要回答的问题:
• 从ML的角度来看,这个ML应用程序将帮助解决什么业务问题?
• ML app需要预测什么?它将接收什么输入?
• 是否有足够的数据来训练模型和度量有效性?这些数据是否干净、可访问等?用于实验的数据可能是人工清理的。生产培训数据也需要清理。
• 是否有初步的实验(在开发人员/笔记本/笔记本电脑环境中)显示出一种有前景的算法方法来交付必要的预测/质量?
• ML应用程序需要如何与业务应用程序(REST、Batch等)集成?
一旦这些问题得到了回答,您就可以大致了解ML应用程序在MVP中需要什么。这为步骤2和步骤3奠定了基础。
步骤2:开列状态清单:你有什么?
一旦确定了用例,下一步是整合起始状态,以便您可以将旅程映射到目的地。启动状态的典型特征包括以下来自所需机器学习应用程序的开发人员级原型的构件:
• 数据科学家环境中的一个软件程序,如Jupyter笔记本、R开发人员环境、Matlab等。该代码通常执行初始(有前景的)机器学习模型和实验。
• 此代码已通过一个或多个位于数据湖泊或数据库等中的数据集运行。这些数据湖泊和数据库是客户正常数据中心基础设施环境的一部分。这些数据集可能存在于笔记本电脑中,也可能需要移动到数据湖中。
• 在这些开发人员环境中运行了培训代码,有时还存在示例模型。
在许多方面,这种启动状态类似于其他(non-ML)域中的软件原型。与其他软件一样,原型代码可能没有使用生产版本中所期望的所有连接器、规模因素和加强功能来编写。例如,如果生产版本需要从云对象存储库读取数据,而您的实验需要读取存储在笔记本电脑的数据,则需要将对象存储连接器添加到生产管道代码中。类似地,如果您的实验代码在出现错误时退出,这对于生产来说可能是不可接受的。
还有一些特定于机器学习的挑战。例如:
• 这里生成的模型可能需要导入来引导生产管道。
• 可能需要将特定于ML的检测添加到代码中,例如,报告ML统计信息、生成特定于ML的警报、收集检测(执行的统计数字)作长期分析等用。
步骤3:定义你的MVP产品
现在您已经准备好定义MVP:您将在生产中使用的第一个基本服务。为此,您需要确定第一个生产位置,即代码运行的第一个位置。
• 这在很大程度上取决于您的环境。一个短期的选择可能是您为其他应用程序(non-ML等)提供的数据中心基础设施中。您可能还有一个长期的观点,包括与软件或云和服务策略的其他方面的集成。
除了确定第一个位置外,你还需要处理以下事项:
• 访问数据湖等可以是通用的,除非组织(特别是企业)设置了应用于分析使用的特定数据访问限制。
• 必须安装机器学习引擎(Spark、TensorFlow等)。如果使用容器,这可能是非常通用的。如果使用分析引擎,它可能具有很高的机器学习特性。需要找到并包含所有依赖项(您的管道运行需要访问哪些库,等等)。
• 需要进行分析引擎和容器大小调整,以确保初始测试和调试的性能范围是合理的。测试和调试将是迭代的。
• 需要定义升级过程。例如,如果您决定升级您的管道代码,并且它需要以前没有安装的新库,那么您将需要考虑如何处理它。
步骤4:为生产准备代码
现在,您需要考虑您的实验(如果有的话)中的哪些代码需要在生产中使用。如果您不打算在生产中重新培训模型,那么您需要考虑的代码只是用于推理。在这种情况下,一个简单的解决方案可能是部署由供应商提供的预定义推理管道。
如果您计划在生产环境中进行再培训,或者有一个自定义需求,但是预构建的推理管道不能满足这个需求,那么您将需要为生产准备您的实验代码,或者构建任何您的实验代码中没有的新的生产功能。作为其中一部分,你需要考虑以下几点:
• 淬火生产(错误处理等)
• 模块化以便重用
• 调用连接器,以便在步骤3中标识的生产位置之间检索和存储数据。
• 您将把代码保存在哪里(Git等)?
? 您应该添加什么工具来确保您可以检测和调试模型的生产问题?
步骤5:构建一个机器学习应用程序
既然已经准备好了所有代码块,现在就可以构建机器学习应用程序了。为什么这与只是构建管道不同?为了在生产中可靠地执行,还需要确保编排管道、管理和版本模型以及其他输出等的机制也到位。这包括如何在生成新模型时更新管道,以及如何在改进了管道代码后将新代码投入生产。
如果您正在让生产机器学习运行,您可以在运行时中配置ML应用程序,并将其连接到您在步骤1到4创建的代码和其他构件中。图2显示显示了一个由ParallelM在MCenter运行时生成的示例ML应用程序。
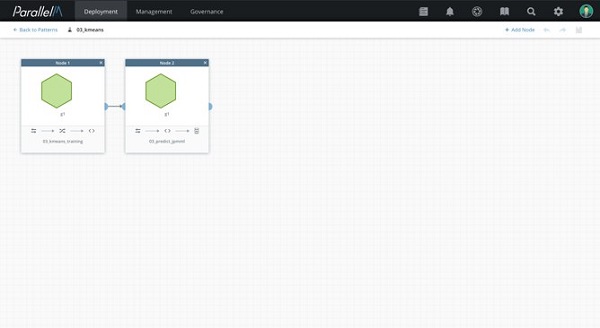
图2:一个ML应用程序示例
步骤6:将机器学习应用程序部署到生产环境中
一旦有了机器学习应用程序,就可以部署了!要进行部署,您需要启动ML应用程序(或其管道)并将它们连接到您的业务应用程序。例如,如果使用REST,您的ML应用程序将在启动时创建一个REST端点,您的业务应用程序可以调用它进行任何预测(参见图3)。
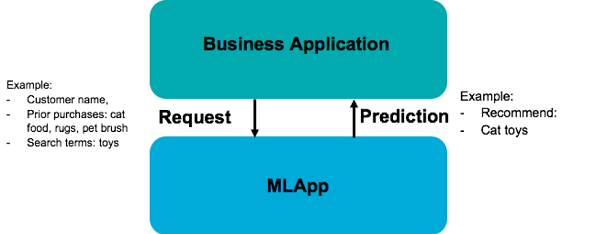
图3:ML应用程序生成一个REST服务供业务应用程序使用
请注意,部署可以被认为是MVP的“完成”,但这绝不是您旅程的终点。一个成功的机器学习服务将运行数月或数年,在此期间需要管理、维护和监视。
根据您在步骤5中选择的解决方案,部署可以是自动化的,也可以是手动的。MLOps运行时工具提供自动部署。如果您在运行机器学习应用程序时没有这些工具,您可能需要编写脚本和其他软件来帮助您部署和管理管道。您可能还需要与您的IT组织合作来完成此任务。
步骤7:做得更好
回想一下,在步骤3中,您可能选择了一个短期位置来运行生产ML MVP。在步骤5和步骤6中部署MVP之后,您可能需要进一步的步骤来检查MVP的结果,并重新考虑关键的基础设施决策。现在代码/MVP至少在第一个基础设施中测试和运行,您可以比较和对比不同的基础设施,看看是否需要改进。
步骤8:持续优化
注意,步骤3 - 7在此机器学习应用程序服务的业务用例的生命周期内不断重复。机器学习应用程序本身可以重新定义、返回、传输到新的基础设施,等等。您可以看到MVP是如何被使用的,您从您的业务中得到了什么反馈,并相应地进行改进。
MLOps还有什么?
MLOps是在生产环境中部署和管理模型的综合实践。上面的步骤显示了如何通过部署第一个模型开始使用MLOps。一旦您采取了上述步骤,您将在生产中至少有一个机器学习应用程序,然后您将需要在其生命周期中对其进行管理。然后,您可能需要考虑ML生命周期管理的其他方面,例如管理模型的治理,遵守您的业务的任何监管需求,制定kpi以评估ML模型为业务应用程序带来的好处,等等。
我们希望这篇文章对你有用。
(编译自:How to Move from Experimentation to Building Production Machine Learning Applications,作者: Nisha Talagala)